

















KD-crowd: A knowledge distillation framework for learning from crowds
Crowdsourcing efficiently delegates tasks to crowd workers for labeling, though their varying expertise can lead to errors. A key task is estimating worker expertise to infer true labels. However, the noise transition matrix-based methods for modeling worker expertise often overfit annotation noise due to oversimplification or inaccurate estimations. To solve the problems, a research team […]
Crowdsourcing efficiently delegates tasks to crowd workers for labeling, though their varying expertise can lead to errors. A key task is estimating worker expertise to infer true labels. However, the noise transition matrix-based methods for modeling worker expertise often overfit annotation noise due to oversimplification or inaccurate estimations.
To solve the problems, a research team led by Shao-Yuan LI published their new research on 12 Mar 2024 in Frontiers of Computer Science co-published by Higher Education Press and Springer Nature.
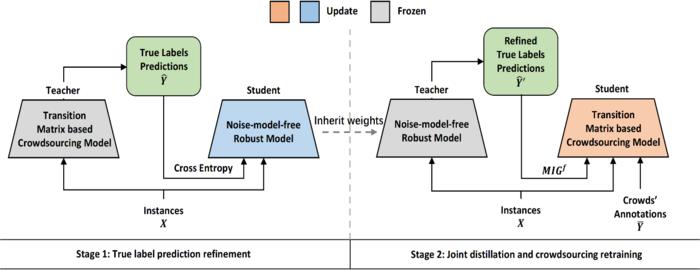
The team proposed a knowledge distillation-based framework KD-Crowd, which leverages noise-model-free learning techniques to refine crowdsourcing learning. Besides, the team also proposed one f-mutual information gain-based knowledge distillation loss to prevent the student from memorizing serious mistakes of the teacher model. Compared with the existing research results, the proposed method demonstrated both on synthetic and real-world data, attains substantial improvements in performance.
Future work can focus on testing the effectiveness of this framework on regular single-source noisy label learning scenarios with complex instance-dependent noise and investigating more intrinsic patterns in crowdsourced datasets.
DOI: 10.1007/s11704-023-3578-7
Credit: Shao-Yuan LI, Yu-Xiang ZHENG, Ye SHI, Sheng-Jun HUANG, Songcan CHEN
Crowdsourcing efficiently delegates tasks to crowd workers for labeling, though their varying expertise can lead to errors. A key task is estimating worker expertise to infer true labels. However, the noise transition matrix-based methods for modeling worker expertise often overfit annotation noise due to oversimplification or inaccurate estimations.
To solve the problems, a research team led by Shao-Yuan LI published their new research on 12 Mar 2024 in Frontiers of Computer Science co-published by Higher Education Press and Springer Nature.
The team proposed a knowledge distillation-based framework KD-Crowd, which leverages noise-model-free learning techniques to refine crowdsourcing learning. Besides, the team also proposed one f-mutual information gain-based knowledge distillation loss to prevent the student from memorizing serious mistakes of the teacher model. Compared with the existing research results, the proposed method demonstrated both on synthetic and real-world data, attains substantial improvements in performance.
Future work can focus on testing the effectiveness of this framework on regular single-source noisy label learning scenarios with complex instance-dependent noise and investigating more intrinsic patterns in crowdsourced datasets.
DOI: 10.1007/s11704-023-3578-7
Journal
Frontiers of Computer Science
DOI
10.1007/s11704-023-3578-7
Method of Research
Experimental study
Subject of Research
Not applicable
Article Title
KD-Crowd: a knowledge distillation framework for learning from crowds
Article Publication Date
12-Mar-2024
What's Your Reaction?













